
Soupault 1.7.0 release
Date:
Soupault 1.7.0 is available for download. With this new version, you can pipe the content of elements through any external preprocessor (e.g. for syntax highlighting), use multiple different index “views”, and specify default values for custom index fields.
Preprocessing element content
Most static site generators include some syntax highlighting functionality, but in soupault it was hard to do until this release. Your best bet would be to write a Lua plugin that calls an external program. Now there’s a general and easy to use way to do syntax highlighting and much more than that.
Thanks to a patch by Martin Karlsson, you now can pipe the content of any element through any external program.
This is done with the new preprocess_element widget. It runs an external program specified in the
command option and sends the element content to its standard input.
-
Tag name is passed in
TAG_NAMEvariable. -
Element attributes are passed in variables prefixed with
ATTR:ATTR_ID,ATTR_CLASS,ATTR_SRC… -
Page file path is passed in
PAGE_FILE
For example, this is how you can run source code snippets inside elements like <pre class="language-python">
through Andre Simon’s highlight tool for syntax highlighting:
# Runs the content of <* class="language-*"> elements through a syntax highlighter
[widgets.highlight]
widget = "preprocess_element"
selector = '*[class^="language-"]'
command = 'highlight -O html -f --syntax=$(echo $ATTR_CLASS | sed -e "s/language-//")'
You can find a live example of that highlighting in baturin.org/code/japh for example.
That widget also supports all action options,
including insert_before/after and replace_element, so you can either keep the original element in the page, or completely replace it with a rendered version.
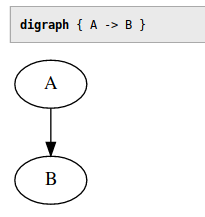
For example, this is how you can add an inline SVG version of every Graphviz graph in your page and also highlight the graph source:
[widgets.graphviz-svg]
widget = 'preprocess_element'
selector = 'pre.language-graphviz'
command = 'dot -Tsvg'
action = 'insert_after'
[widgets.highlight]
after = "graphviz-svg"
widget = "preprocess_element"
selector = '*[class^="language-"]'
command = 'highlight -O html -f --syntax=$(echo $ATTR_CLASS | sed -e "s/language-//")'
The result will look like this:
…or you can generate a PNG version of it using its id attribute for the file name,
and replace the element with a picture. Better make a script instead of doing inline shell hackery,
but the point remains:
[widgets.graphviz-png]
widget = 'preprocess_element'
selector = '.graphviz-png'
command = 'dot -Tpng > $(dirname $PAGE_FILE)/$ATTR_ID.png && echo \<img src="$ATTR_ID.png"\>'
action = 'replace_element'
Multiple index views
In previous versions, all section indices had to follow the same format. That’s quite limiting, since one may want to have a blog feed in one section, but a simple list of pages in another, and there was no way to do that.
Now you can define multiple index “views” that present the same data in a different format.
Index views are defined as subtables of [index.views]. You can use either dotted syntax like
[index.views.blog], or inline tables, from TOML’s point of view it’s the same.
Each of those tables must have an index_selector option that defines where the index of that kind
if inserted. It must also have either index_item_template option with a Mustache template string,
or an index_processor option with a path to a script. If both index_processor and index_item_template
options are given, it will use index_processor and warn you in the log.
[index.views.title-and-date]
index_selector = "div#index-title-date"
index_item_template = "<li> <a href=\"{{url}}\">{{{title}}}</a> ({{date}})</li>"
[index.views.custom]
index_selector = "div#custom-index"
index_processor = 'scripts/my-index-generator.pl'
The original index_selector and index_item_template/index_processor options in the [index]
table are still there, so old configs will work as usual. However, you can make soupault ignore
them with use_default_view = false and use named views exclusively. This is useful if you want
to omit the index_selector option since it defaults to body and would insert an unwanted index
if you omit it.
Here’s an example that will insert a blog feed into the page if it has a <div id="blog-index">,
but a simple list of pages if it has <div id="simple-index">.
[index]
index = true
index_title_selector = ["h1#post-title", "h1"]
index_date_selector = ["time#post-date", "time"]
index_excerpt_selector = ["p#post-excerpt", "p"]
newest_entries_first = true
use_default_view = false
[index.views.simple]
index_selector = "div#simple-index"
index_item_template = "<li> <a href=\"{{url}}\">{{{title}}}</a> </li>"
[index.views.blog]
index_selector = "div#blog-index"
index_item_template = """
<h2><a href="{{url}}">{{title}}</a></h2>
<p><strong>Last update:</strong> {{date}}.</p>
<p>{{{excerpt}}}</p>
<a href="{{url}}">Read more</a>
"""
If your page has both <div id="blog-index"> and <div id="simple-index">, then both kinds of
index will be inserted. You can use this to display the same section index in different formats,
for example, grouped by date and by author. Since soupault doesn’t have taxonomies in the same
sense as Hugo or Jekyll, that’s one way to make up for it (the other way is exporting the index
to JSON and generating taxonomy pages with an external script, then re-running soupault).
Default values for custom index fields
With soupault, you can extract arbitrary metadata from pages using the custom fields mechanism. That’s how the stupid reading time field in the blog feed of this site is made (I’ll be frank, testing that feature is the only readon I’ve added it).
An element that is supposed to hold that metadata may be missing from the page (just like it can be missing from “front matter”, nothing new here). You can handle it in the script that handles that data, but if something has a sensible default, why not add a way to set it?
Now you can do it with the default option in your custom field subtable. If default is given,
then missing values will be substituted with it. If not, the field will be null, as before.
[index.custom_fields]
category = { selector = "#category", default = "misc" }
Internals
If you are building from source, you’ll need OCaml 4.08 or later. I’ve switched from ocaml-monadic
syntax extension to the new built-in monadic operators introduced in 4.08, so there’s one less dependency.
Since you can easily install the latest version with opam switch create 4.09.0, this shouldn’t be an issue.
I’ve also took time to make cross-versions of all missing dependencies for opam-cross-windows, so the Windows version is compiled on a GNU/Linux host now. This seriously simplifies the release procedure for me, since I don’t need to have a proprietary OS in the pipeline or rely on a third-party service. Fun fact: I’m testing those builds in Wine, and they work rather well there. The pull requests are not merged as of now and I’m using a local fork of that repository, but once they are merged, I hope it will simplify CI and release procedure for more people than just me.