
Reference manual
→ Installation
→ Binary release packages
Soupault is distributed as a single, self-contained executable, so installing it from a binary release package it trivial.
You can download it from files.baturin.org/software/soupault. Prebuilt executables are available for Linux (x86-64, statically linked), macOS (x86-64), and Microsoft Windows (32-bit, Windows 7 and newer).
Just unpack the archive and copy the executable wherever you want.
Prebuilt executables are compiled with debug symbols. It makes them a couple of megabytes larger than they could be, but you can get better error messages if something goes wrong.
If you encounter an internal error, you can get an exception trace by running it with OCAMLRUNPARAM=b environment variable.
→ Building from source
If you are familiar with the OCaml programming language, you may want to install from source.
Since version 1.6, soupault is available from the opam repository. If you already have opam installed, you can install it with opam install soupault.
If you want the latest development version, the git repository is at github.com/dmbaturin/soupault. There’s also a SourceHut mirror at git.sr.ht/~dmbaturin/soupault.
To build a statically linked executable for Linux, identical to the official one, first install a +musl+static+flambda compiler flavor, then uncomment the (flags (-ccopt -static)) line in src/dune.
→ Using soupault on Windows
Windows is a supported platform and soupault includes some fixups to account for the differences. This document makes a UNIX cultural assumption throughout, but most of the time the same configs will work on both systems. Some differences, however, require user intervention to resolve.
If a file path is only used by soupault itself, then the UNIX convention will work, i.e. file = 'templates/header.html' and file = 'templates\header.html' are both valid options for the include widget.
However, if it’s passed to something else in the system, then you must use the Windows convention with back slashes.
This applies to the preprocessors, the command option of the exec widget, and the index_processor option.
So, if you are on Windows, remember to adjust the paths if needed, e.g.:
[widgets.some-script]
widget = 'exec'
command = 'scripts\myscript.bat'
selector = 'body'
Note that inside double quotes, the back slash is an escape character, so you should either use single quotes for such paths ('scripts\myscript.bat') or use a double back slash ("scripts\\myscript.bat").
→ Overview
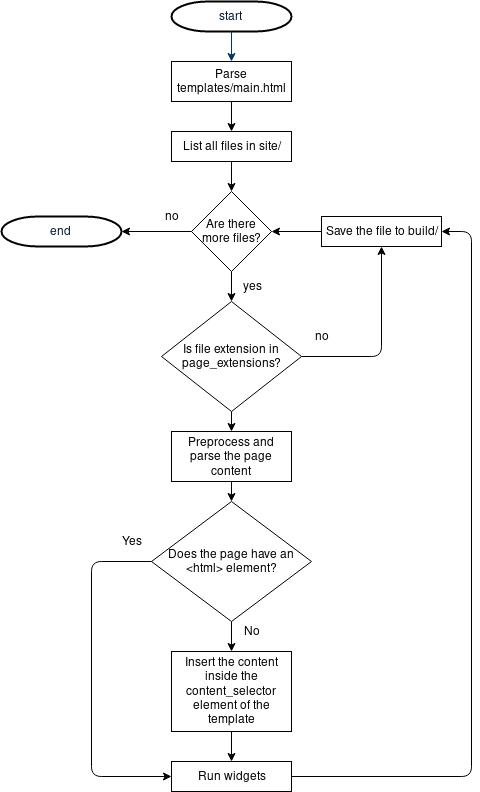
In the website generator mode (the default), soupault takes a page “template”—an HTML file devoid of content, parses it into an element tree, and locates the content container element inside it.
By default the content container is <body>, but you can use any selector: div#content (a <div id="content"> element), article (an HTML5 <article> element), #post (any element with id="post")
or any other valid CSS selector.
Then it traverses your site directory where page source files are stored, takes a page file, and parses it into an HTML element tree too.
If the file is not a complete HTML document (doesn’t have an <html> element in it), soupault inserts it into the content container element of the template. If it is a complete page, then it goes straight to the next step.
The new HTML tree is then passed to widgets—HTML rewriting modules that manipulate it in different ways: incude other files or outputs of external programs into specific elements, create breadcrumbs for your page, they may delete unwanted elements too.
Processed pages are then written to disk, into a directory structure that mirrors your source directory structure.
Here is a simplified flowchart:
→ Basic configuration
Very few soupault settings are fixed, and most can be changed in the configuration file. This is the settings from the default config that soupault --init generates:
[settings]
# Stop on page processing errors?
strict = true
# Display progress?
verbose = false
# Display detailed debug output?
debug = false
# Where input files (pages and assets) are stored.
site_dir = "site"
# Where the output goes
build_dir = "build"
# Files inside the site/ directory can be treated as pages or static assets,
# depending on the extension.
#
# Files with extensions from this list are considered pages and processed.
# All other files are copied to build/ unchanged.
#
# Note that for formats other than HTML, you need to specify an external program
# for converting them to HTML (see below).
page_file_extensions = ["htm", "html", "md", "rst", "adoc"]
# Files with these extensions are ignored.
ignore_extensions = ["draft"]
# Soupault can work as a website generator or an HTML processor.
#
# In the "website generator" mode, it considers files in site/ page bodies
# and inserts them into the empty page template stored in templates/main.html
#
# Setting this option to false switches it to the "HTML processor" mode
# when it considers every file in site/ a complete page and only runs it through widgets/plugins.
generator_mode = true
# Files that contain an element are considered complete pages rather than page bodies,
# even in the "website generator" mode.
# This allows you to use a unique layout for some pages and still have them processed by widgets.
complete_page_selector = "html"
# Website generator mode requires a page template (an empty page to insert a page body into).
# If you use "generator_mode = false", this file is not required.
default_template = "templates/main.html"
# Page content is inserted into a certain element of the page template. This option is a CSS selector
# used for locating that element.
# By default the content is inserted into the
content_selector = "body"
# Whether to keep the original page doctype or not
keep_doctype = false
# Doctype to use for pages that don't have one (when keep_doctype = true)
# or for all pages (when keep_doctype = false)
doctype = "<!DOCTYPE html>"
# Enables or disables clean URLs.
# When false: site/about.html -> build/about.html
# When true: site/about.html -> build/about/index.html
clean_urls = true
# Since 1.10, soupault has plugin auto-discovery
# A file like plugins/my-plugin.lua will be registered as a widget named my-plugin
plugin_discovery = true
plugin_dirs = ["plugins"]
Note that if you create a soupault.conf file before running soupault --init, it will not overwrite that file.
In this document, whenever a specific site or build dir has to be mentioned, we’ll use default values.
If you misspell and option or make another mistake, soupault will notify you about an invalid option and try to suggest a correction.
Note that the config is typed and wrong value type has the same effect as missing option. All boolean values must be true or false (without quotes), all integer values must not have quotes around numbers, and all strings must be in single or double quotes.
→ Custom directory layouts
If you are using soupault as an HTML processor, or using it as a part of a CI pipeline, typical website generator approach with a single “project directory” may not be optimal.
You can override the location of the config using an environment variable SOUPAULT_CONFIG.
You can also override the locations of the source and destination directories with --site-dir and --build-dir options.
Thus it’s possible to run soupault without a dedicated project directory at all:
SOUPAULT_CONFIG="mysite.conf" soupault --site-dir some-input-dir --build-dir some-other-dir
→ Page processing
→ Page templates
In soupault’s terminology, a page template is simply an HTML file without content—an empty page. Soupault does not use a template processor for assembling pages, instead it injects the content into the element tree. This way any empty HTML page can serve as a soupault “theme”.
This is the default configuration:
[settings]
default_template_file = "templates/main.html"
default_content_selector = "body"
default_content_action = "append_child"
It means that when soupault processes a page, it first loads and parses the HTML from templates/main.html, then parses a page, processes it,
and inserts the result in the <body> element of the template, after the last existing child element.
The default_content_selector option can be any valid CSS3 selector. The default_content_action can be an valid content insertion action.
This is the miminal template good for default_content_selector = "body":
<html>
<body>
<!-- content goes here -->
</body>
</html>
→ Additional templates
It’s possible to use multiple templates. Note that additional templates must be limited to specific pages with limiting options options!
Note that you cannot omit the default template.
[settings]
default_template_file = "templates/main.html"
default_content_selector = "body"
[templates.funny-template]
file = "templates/funny-template.html"
content_selector = "div#fun-content"
content_action = "prepend_child"
section = "fun/"
→ Page files
With default config, page files are stored in site/.
→ Page file extensions
Files in the site directory can be treated as pages or assets, depending on their extension.
The page_file_extensions option defines which files are treated as pages. This is the default:
[settings]
page_file_extensions = ["html", "htm", "md", "rst", "adoc"]
Page files are parsed as HTML, processed, and written to the build directory. Asset files are copied to the build directory unchanged.
→ Page preprocessors
Soupault has no built-in support for formats other than HTML. Instead, it allows you to specify external preprocessor programs to convert other formats to HTML.
A preprocessor program must take a page file as an argument and must write generated HTML to standard output.
For example, this configuration will make soupault preprocess Markdown files with cmark.
[preprocessors]
md = "cmark --unsafe --smart"
Preprocessor commands are executed in the system shell, so it’s fine to use relative paths and specify command arguments. Page file name is appended to the command string.
→ Partial and complete pages
Soupault allows you to have pages with a unique, non-templated layout even in generator mode.
If a page has an <html> element in it, it’s assumed to be a complete page.
Complete pages are exempt from templating, they are only parsed and processed by widgets.
If a page doesn’t have an <html> element in it, its content is inserted in a page template first.
Note that the selector used to check for “completeness” is a configurable option:
[settings]
complete_page_selector = "html"
→ Clean URLs
Soupault uses clean URLs by default. If you add a page to site/, for example, site/about.html, it will turn into build/about/index.html so that it can be accessed as https://mysite.example.com/about.
Index files are simply copied to the target directory.
-
site/index.html→build/index.html -
site/about.html→build/about/index.html -
site/papers/theorems-for-free.html→build/papers/theorems-for-free/index.html
Note: having a page named foo.html and a section directory named foo/ results in undefined behaviour when clean URLs are on. Don’t do that to avoid unpredictable results.
This is what soupault will make from a source directory, when clean URLs are enabled:
$ tree site/
site/
├── about.html
├── cv.html
└── index.html
$ tree build/
build/
├── about
│ └── index.html
├── cv
│ └── index.html
└── index.html
→ Disabling clean URLs
If you’ve had a website for a long time and there are links to your page that will break if you change the URLs, you can make soupault mirror your site directory structure exactly and preserve original file names.
Just add clean_urls = false to the [settings] sectione of your soupault.conf file.
[settings]
clean_urls = false
→ Soupault as an HTML processor
If you want to use soupault with an existing website and don’t want the template functionality, you can switch it from a website generator mode to an HTML processor more where it doesn’t use a template and doesn’t require the default_template to exist.
Recommended settings for the preprocessor mode:
[settings]
generator_mode = false
clean_urls = false
→ Metadata extraction and rendering
Soupault can extract metadata from pages using CSS selectors, similar to what web scrapers are doing. This is more flexible than “front matter”, and allows you to automatically generate index pages for existing websites, without having to edit their pages.
What you do with extracted metadata is up to you. You can simply export it to JSON for further processing, like generating an RSS/Atom feed, or creating taxonomy pages with an external script. You can also tell soupault to generate HTML from the index data. You can also combine both approaches.
Metadata extraction is disabled by default. You need to enable it first:
[index]
index = true
→ Index settings
These are the basic settings:
[index]
# Whether to extract metadata and generate indices or not
# Default is false, set to true to enable
index = false
# Which index field to use as a sorting key
# sort_by =
# By default entries are sorted in descending order.
# This means if you sort by date, newest entries come first.
sort_descending = true
# Date format for sorting
# Default %F means YYYY-MM-DD
# For other formats, see http://calendar.forge.ocamlcore.org/doc/Printer.html
index_date_formats = ["%F"]
# extract_after_widgets = []
→ Index fields
Soupault doesn’t have a built-in “content model”. Instead, it allows you to define what to extract from pages, in the spirit of microformats.
This is the configuration for this very site:
[index.fields]
title = {
selector = ["h1#post-title", "h1"]
}
date = {
selector = ["time#post-date", "time"],
extract_attribute = "datetime",
fallback_to_content = true
}
excerpt = {
selector = ["p#post-excerpt", "p"]
}
reading_time = {
selector = "span#reading-time"
}
The selector field is either a single CSS selector or a list of selectors that define what to extract
from the page. Here, selector = ["p#post-excerpt", "p"] means “use p#post-excerpt for the excerpt,
but if there’s no such element, just use the first paragraph”.
By default, soupault will extract only the first element, but you can change that with select_all = true.
You can also set the default value with default option (only for fields without select_all = true).
As you can see from the date field definition, it’s possible to make soupault extract an attribute
rather than content. The fallback_to_content option defines what soupault will do if an element has
no such attribute. With fallback_to_content = true it will extract the element content instead,
while if it’s false, it will leave the field undefined.
→ Built-in index fields
Soupault provides technical metadata of the page as built-in fields.
- url
- Absolute page URL path, like /papers/simple-imperative-polymorphism (or /papers/simple-imperative-polymorphism.html, if clean URLs are disabled)
- nav_path
-
A list of strings that represents the logical section path, e.g. for
site/pictures/cats/grumpy.htmlit will be["pictures", "cats"]. - page_file
- Original page file path.
→ Index views
Soupault can insert HTML rendered from site metadata into the site index pages. By default those are pages
named index.*.
Note that you cannot insert an index into an arbitrary page, and you cannot extract any metadata from an index page.
The way index data is rendered is defined by “index views”. You can have any number of views.
Which view is used is determined by the index_selector option. It’s possible to use multiple views on the same page,
e.g. if you want to display lists of posts grouped by date and by author.
There are three options that can define view rendering:
-
index_item_template— a jingoo template for an individual item, applied to each index data entry -
index_template— a Jingoo template for the entire index. -
index_processor— external script that receives index data (in JSON) to stdin and write HTML to stdout.
Example:
[index.views.blog]
index_selector = "#blog-index"
index_item_template = """
<h2><a href="{{url}}">{{title}}</a></h2>
<p><strong>Last update:</strong> {{date}}.</p>
<p><strong>Reading time:</strong> {{reading_time}}.</p>
<p>{{excerpt}}</p>
<a href="{{url}}">Read more</a>
"""
By default, soupault will render an index of the current section, e.g. site/blog/index.html page will display an index of all pages in the
site/blog/ directory.
If you want to display an index of a different section, or present the same index in different ways, you can add limiting options to the view, like this:
[index.views.blog-summary]
section = "blog/"
index_processor = "scripts/blog-summary.py"
→ Interaction with widgets
Soupault first inserts rendered index data, then runs widgets. This is to allow widgets to modify HTML generated by index processors.
Metadata extraction happens as early as possible. By default, it happens before any widgets have run, to avoid adverse interaction with widgets. However, if you want to extract something from output of a widget, you can tell soupault which widgets to run before extracting metadata.
Suppose you want metadata extraction to happen only after widgets foo and bar have run. You can do it with this config:
[index]
extract_after_widgets = ["foo", "bar"]
Note that it doesn’t mean that soupault will schedule widgets foo and bar to run before everything else. It doesn’t mean that
soupault will not schedule any other widgets to run before metadata extraction happens. It only means that metadata extraction
will happen immediately after the last of foo and bar widgets have run.
Thus, if you have a setup where some widgets produce metadata you want extracted (“producers”), and other widgets that modify the rendered index (“consumers”), you may need to specify all “producers” as dependencies for “consumers” to ensure correct ordering.
For example, if you want a widget prettify-blog-index to run only after add-tags and add-reading-time have run,
this is the only way to guarantee it:
[index]
extract_after_widgets = ["add-tags", "add-reading-time"]
...
[widgets.prettify-blog-index]
after = ["add-tags", "add-reading-time"]
...
→ Exporting metadata to JSON
If built-in functionality is not enough, you can export the site index data to a JSON file and process it with external scripts.
JSON export is disabled by default an needs to be enabled explicitly:
[index]
dump_json = "path/to/file.json"
This way you can use a TeX-like workflow:
- Run soupault so that index file is created.
- Run your custom index generator and save generated taxonomy pages to site/.
- Run soupault one more time to have them included in the build.
To save time and avoid useless operations, you can run soupault --index-only.
With this option, soupault will stop after extracting the metadata and exporting it to JSON.
It will run widgets that index extraction depends on (that is, those specified in extract_after_widgets),
but will not run the rest of the widget, nor will it copy assets or generate pages.
→ Widgets
Widgets mo Soupault has built-in widgets for deleting specific HTML elements, including files into pages, setting page title and so on.
→ Widget behaviour
Widgets that require a selector option first check if there’s an element matching that selector in the page. If there’s no such element, they do nothing, since they wouldn’t have a place to insert their output anyway.
Thus, the simplest way to ensure a widget doesn’t run on a particular page is to make sure that page doesn’t have its target element.
If a page has more than one element matching the same selector, the first element is used as widget’s target.
→ Widget configuration
Widget configuration is stored in the [widgets] table. The TOML syntax for nested tables is [table.subtable], therefore, you will have entries like [widgets.foo], [widgets.bar] and so on.
Widget subtable names are purely informational and have no effect, widget type is determined by the widget option.
Therefore, if you want to use a hypothetical frobnicator widget, your entry will look like:
[widgets.frobnicate]
widget = "frobnicator"
selector = "div#frob"
It may seem confusing and redundant, but it allows you to use more than one widget of the same type.
[widgets.insert-header]
widget = "include"
file = "templates/header.html"
selector = "div#header"
[widgets.insert-footer]
widget = "include"
file = "templates/footer.html"
selector = "div#footer"
→ Choosing where to insert the output
By default, widget output is inserted after the last child of its target element.
If you are modifying existing pages or just want more control and flexibility, you can specify the position explicitly using an action option.
For example, you can insert a header file before the first element in the page <body>:
[widgets.insert-header]
widget = "include"
file = "templates/header.html"
selector = "body"
action = "prepend_child"
Or insert a table of contents before the first <h1> element (it a page has it):
[widgets.table-of-contents]
widget = "toc"
selector = "h1"
action = "insert_before"
You can find the complete list of valid actions in the glossary.
→ Limiting widgets to pages or sections
If the widget target comes from the page content rather than the template, you can simply not include any elements matching its selector option.
Otherwise, you can explicitly set a widget to run or not run on specific pages or sections.
All options from this section can take either a single string, or a list of strings.
→ Limiting to pages or sections
There are page and section options that allow you to specify exact paths to specific pages or sections. Paths are relative to your site directory.
The page option limits a widget to an exact page file, while the section option applies a widget to all files in a subdirectory.
[widgets.site-news]
# only on site/index.html and site/news.html
page = ["index.html", "news.html"]
widget = "include"
file = "includes/site-news.html"
selector = "div#news"
[widgets.cat-picture]
# only on site/cats/*
section = "cats"
widget = "insert_html"
html = "<img src=\"/images/lolcat_cookie.gif\" />"
selector = "#catpic"
→ Excluding sections or pages
It’s also possible to explicitly exclude pages or sections.
[widgets.toc]
# Don't add a TOC to the main page
exclude_page = "index.html"
...
[widgets.evil-analytics]
exclude_section = "privacy"
...
→ Using regular expressions
When nothing else helps, path_regex and exclude_path_regex options may solve your problem. They take a Perl-compatible regular expression (not a glob).
[widgets.toc]
# Don't add a TOC to any section index page
exclude_path_regex = '^(.*)/index\.html$'
...
[widgets.cat-picture]
path_regex = 'cats/'
→ Widget processing order
The order of widgets in your config file doesn’t determine their processing order. By default, soupault assumes that widgets are independent and can be processed in arbitrary order. In future versions they may even be processed in parallel, who knows.
This can be an issue if one widget relies on putput from another. In that case, you can order widgets explicitly with the after parameter.
It can be a single widget (after = "my-widget") or a list of widgets (after = ["some-widget", "another-widget"]).
Here is an example. Suppose in the template there’s a <div id="breadcrumbs"> where breadcrumbs are inserted by the add-breadcrumbs widget.
Since there may not be breadcrumbs if the page is not deep enough, that <div> may be left empty, and that’s not neat. We can remove empty breadcrumb containers
with a delete_element widget, but we need to make sure it only runs after breadcrumbs widget has run.
## Breadcrumbs
[widgets.add-breadcrumbs]
widget = "breadcrumbs"
selector = "#breadcrumbs"
...
## Remove div#breadcrumbs if the breadcrumbs widget left it empty
[widgets.cleanup-breadcrumbs]
widget = "delete_element"
selector = "#breadcrumbs"
only_if_empty = true
# Important!
after = "add-breadcrumbs"
...
→ Limiting widgets to “build profiles”
Sometimes you may want to enable certain widgets only for some builds. For example, include analytics scripts only in production builds. It can be done with “build profiles”.
For example, this way you can only include includes/analytics.html file in your pages for a build profile named “live”:
[widgets.analytics]
profile = "live"
widget = "include"
file = "includes/analytics.html"
selector = "body"
Soupault will only process that widget if you run soupault --profile live. If you run soupault --profile dev, or run it without the --profile option, it will ignore that widget.
→ Built-in widgets
→ File and output inclusion
These widgets include something into your page: a file, a snippet, or output of an external program.
→ include
The include widget simply reads a file and inserts its content into some element.
The following configuration will insert the content of templates/header.html file into an element with id="header" and the content of templates/footer.html into an element with id="footer".
[widgets.header]
widget = "include"
file = "templates/header.html"
selector = "#header"
[widgets.footer]
widget = "include"
file = "templates/footer.html"
selector = "#footer"
This widget provides a parse option that controls whether the file is parsed or included as a text node. Use parse = false if you want to include a file verbatim, with HTML special characters escaped.
Note: you can specify multiple selectors, like selector = ["div#footer", "footer", "body"].
In that case soupault will first try to insert the content in a <div id="footer"> if a page has one,
the try <footer>, and if neither is found, just insert in the page <body>.
→ insert_html
If you only want to insert a small HTML snippet, you can use this widget instead of include.
[widgets.tracking-script]
widget = "insert_html"
html = '<script src="/scripts/evil-analytics.js"> </script>'
selector = "head"
parse = true
→ exec
The exec widget executes an external program and includes its output into an element. The program is executed in the system shell,
so you can write a complete command with arguments in the command option. Like the include widget, it has a parse option that includes the output verbatim if set to false.
Simple example: page generation timestamp.
[widgets.generated-on]
widget = "exec"
selector = "#generated-on"
command = "date -R"
parse = true
→ preprocess_element
This widget processes element content with an external program and includes its output back in the page.
Element content is sent to program’s stdin, so it can be used with any program designed to work as a pipe. HTML entities are expanded, so if you have a > or & in your page, the program gets a > or &.
By default it assumes that the program output is HTML and runs it through an HTML parser. If you want to include its output as text (with HTML special characters escaped), you should specify parse = false.
For example, this is how you can run content of <pre> elements through cat -n to automatically add line numbers:
[widgets.line-numbers]
widget = "preprocess_element"
selector = "pre"
command = "cat -n"
parse = false
You can pass element metadata to the program for better control.
The tag name is passed in the TAG_NAME environment variable, and all attributes are passed in environment variables prefixed with ATTR: ATTR_ID, ATTR_CLASS, ATTR_SRC…
For example, highlight, a popular syntax highlighting tool, has a language syntax option, e.g. --syntax=python.
If your elements that contain source code samples have language specified in a class (like <pre class="language-python">), you can extract the language from the ATTR_CLASS variable like this:
# Runs the content of <* class="language-*"> elements through a syntax highlighter
[widgets.highlight]
widget = "preprocess_element"
selector = '*[class^="language-"]'
command = 'highlight -O html -f --syntax=$(echo $ATTR_CLASS | sed -e "s/language-//")'
Like all widgets, this widget supports the action option.
The default is action = "replace_content", but using different actions you can insert a rendered version of the content alongside the original.
For example, insert an inline SVG version of every Graphviz graph next to the source, and then highlight the source:
[widgets.graphviz-svg]
widget = 'preprocess_element'
selector = 'pre.language-graphviz'
command = 'dot -Tsvg'
action = 'insert_after'
[widgets.highlight]
after = "graphviz-svg"
widget = "preprocess_element"
selector = '*[class^="language-"]'
command = 'highlight -O html -f --syntax=$(echo $ATTR_CLASS | sed -e "s/language-//")'
The result will look like this:
Note: this widget supports multiple selectors, e.g. selector = ["pre", "code"].
→ Environment variables
External programs executed by exec and preprocess_element widgets get a few useful environment variables:
- PAGE_FILE
- Path to the page source file, relative to the current working directory (e.g. site/index.html).
- TARGET_DIR
- The directory where the rendered page will be saved.
This is how you can include page’s own source into a page, on a UNIX-like system:
[widgets.page-source]
widget = "exec"
selector = "#page-source"
parse = false
command = "cat $PAGE_FILE"
If you store your pages in git, you can get a page timestamp from the git log with a similar method (note that it’s not a very fast operation for long commit histories):
[widgets.last-modified]
widget = "exec"
selector = "#git-timestamp"
command = "git log -n 1 --pretty=format:%ad --date=format:%Y-%m-%d -- $PAGE_FILE"
The PAGE_FILE variable can be used in many different ways, for example, you can use it to fetch the page author and modification date from a revision control system like git or mercurial.
The TARGET_DIR variable is useful for scripts that modify or create page assets.
For example, this snippet will create PNG images from Graphviz graphs inside <pre class="graphviz-png"> elements and replace those pre’s with relative links to images.
[widgets.graphviz-png]
widget = 'preprocess_element'
selector = '.graphviz-png'
command = 'dot -Tpng > $TARGET_DIR/graph_$ATTR_ID.png && echo \<img src="graph_$ATTR_ID.png"\>'
action = 'replace_element'
→ Content manipulation
→ title
This widget sets the page <title> based on the content on another element. For example, if you have a page with <h1>About me</h1>,
quite likely you want it to have <title>About me — J. Random Hacker's homepage</title>. With this widget you can avoid doing it by hand.
If a page has a non-empty <title> element, this widget doesn’t touch it.
Example:
[widgets.page-title]
widget = "title"
selector = "h1"
default = "My Website"
append = " on My Website"
prepend = "Page named "
force = false
If selector is not specified, it uses the first <h1> as the title source element by default.
The selector option can be a list. For example, selector = ["h1", "h2", "#title"] means “use the first <h1> if the page has it, else use <h2>, else use anything with id="title", else use default”.
Optional prepend and append parameters allow you to insert some text before and after the title.
If there is no element matching the selector in the page, it will use the default. In that case prepend and append options are ignored.
By default this widget skips pages that don’t have a <title> element. You can override this with force = true, then it will create missing <title> elements.
→ footnotes
The footnotes widget finds all elements matching a selector, moves them to a designated footnotes container, and replaces them with numbered links1. As usual, the container element can be anywhere in the page—you can have footnotes at the top if you feel like it.
[widgets.footnotes]
widget = "footnotes"
# Required: Where to move the footnotes
selector = "#footnotes"
# Required: What elements to consider footnotes
footnote_selector = ".footnote"
# Optional: Element to wrap footnotes in, default is <p>
footnote_template = "<p> </p>"
# Optional: Element to wrap the footnote number in, default is <sup>
ref_template = "<sup> </sup>"
# Optional: Class for footnote links, default is none
footnote_link_class = "footnote"
# Optional: do not create links back to original locations
back_links = true
# Prepends some text to the footnote id
link_id_prepend = ""
# Appends some text to the back link id
back_link_id_append = ""
The footnote_selector option can be a list, in that case all elements matching any of those selectors will be considered footnotes.
By default, the number in front of a footnote is a hyperlink back to the original location. You can disable it and make footnotes one way links with back_links = false.
You can create a custom “namespace” for footnotes and reference links using link_id_prepend and back_link_id_append options. This makes it easier to use custom styling for those elements.
link_id_prepend = "footnote-"
back_link_id_append = "-ref"
→ toc
The toc widget generates a table of contents for your page.
Table of contents is generated from heading tags from <h1> to <h6>.
Here is the ToC configuration from this website:
[widgets.table-of-contents]
widget = "toc"
# Required: where to insert the ToC
selector = "#generated-toc"
# Optional: minimum and maximum levels, defaults are 1 and 6 respectively
min_level = 2
max_level = 6
# Optional: use <ol> instead of <ul> for ToC lists
# Default is false
numbered_list = false
# Optional: Class for the ToC list element, default is none
toc_list_class = "toc"
# Optional: append the heading level to the ToC list class
# In this example list for level 2 would be "toc-2"
toc_class_levels = false
# Optional: Insert "link to this section" links next to headings
heading_links = true
# Optional: text for the section links
# Default is "#"
heading_link_text = "→ "
# Optional: class for the section links
# Default is none
heading_link_class = "here"
# Optional: insert the section link after the header text rather than before
# Default is false
heading_links_append = false
# Maximum level for headings to create section links for. Can be greater than max_level
# Implicitly defaults to max_level
# max_heading_link_level =
# Optional: use header text slugs for anchors
# Default is false
use_heading_slug = true
# Only replace non-whitespace characters when generating heading ids
soft_slug = false
# Force heading ids to lowercase
slug_force_lowercase = true
# You can redefine the whole slugification process using these options
slug_regex = '[^a-zA-Z0-9\-]'
slug_replacement_string = "-"
# Optional: use unchanged header text for anchors
# Default is false
use_heading_text = false
# Place nested lists inside a <li> rather than next to it
valid_html = false
→ Heading anchor options
For the table of contents to work, every heading needs a unique id attribute that can be used as an anchor.
If a heading has an id attribute, it will be used for the anchor. If it doesn’t, soupault has to generate one.
By default, if a heading has no id, soupault will generate a unique numeric identifier for it. This is safe, but not very good for readers (links are non-indicative) and for people who want to share direct links to sections (they will change if you add more sections).
If you want to find a balance between readability, permanence, and ease of maintenance, there are a few ways you can do it and the choice is yours.
The use_heading_slug = true option converts the heading text to a valid HTML identifier.
Right now, however, it’s very aggressive and replaces everything other than ASCII letters and digits with hyphens.
This is obviously a no go for non-ASCII languages, that is, pretty much all languages in the world. It may be implemented more sensibly in the future.
The use_heading_text = true option uses unmodified heading text for the id, with whitespace and all. This is against the rules of HTML, but seems to work well in practice.
Note that use_heading_slug and use_heading_text do not enforce uniqueness.
All in all, for best link permanence you should give every heading a unique id by hand, and for best readability you may want to go with use_heading_text = true.
→ breadcrumbs
The breadcrumbs widget generates breadcrumbs for the page.
The only required parameter is selector, the rest is optional.
Example:
[widgets.breadcrumbs]
widget = "breadcrumbs"
selector = "#breadcrumbs"
prepend = ".. / "
append = " /"
between = " / "
breadcrumb_template = '<a href="{{url}}">{{name}}</a>'
min_depth = 1
The breadcrumb_template is a jingoo template string. The only variables in its environment are url and name.
The min_depth option sets the minimum nesting depth where breadcrumbs appear. That’s the length of the logical navigation path rather than directory path.
There is a fixup that decrements the path for section index pages, that is, pages named index.* by default, or whatever is specified in the index_page option.
Their navigation path is considered one level shorter than any other page in the section, when clean URLs are used. This is to prevent section index pages from having links to themselves.
-
site/index.html→ 0 -
site/foo/index.html→ 0 (sic!) -
site/foo/bar.html→ 1
→ HTML manipulation
→ delete_element
The opposite of insert_html. Deletes an element that matches a selector. It can be useful in two situations:
Another widget may leave an element empty and you want to clean it up. Your pages are generated with another tool and it inserts something you don’t want.
# Who reads footers anyway?
[widgets.delete_footer]
widget = "delete_element"
selector = "#footer"
You can limit it to deleting only empty elements with only_if_empty = true. Element is considered empty if there’s nothing but whitespace inside it.
It’s possible to delete only the first element matching a selector by adding delete_all = false to its config.
→ Plugins
Since version 1.2, soupault can be extended with Lua plugins.
The supported language is Lua 2.5, not modern Lua 5.x. That means no closures and no for loops in particular. Here’s a copy of the Lua 2.5 reference manual.
Plugins are treated like widgets and configured the same way.
You can find ready to use plugins in the Plugins section on this site.
→ Installing plugins
→ Plugin discovery
By default, soupault looks for plugins in the plugins/ directory. Suppose you want to use the Site URL plugin. To use that plugin, save it to plugins/site-url.lua.
Then a widget named site-url will automatically become available. The site_urloption from the widget config will be accessible to the plugin asconfig[“site_url”]`.
[widgets.absolute-urls]
widget = "site-url"
site_url = "https://www.example.com"
You can specify multiple plugin directories using the plugin_dirs option under [settings]:
[settings]
plugin_dirs = ["plugins", "/usr/share/soupault/plugins"]
If a file with the same name is found in multiple directories, soupault will use the file from the first directory in the list.
You can also disable plugin discovery and load all plugins explicitly.
[settings]
plugin_discovery = false
→ Explicit plugin loading
You can always load plugins explicitly, whether plugin discovery is enabled or not. This can be useful if you want to:
- load a plugin from an unusual directory
- give the plugin widget your own name
- replace a built-in widget with a plugin
Suppose you want the widget of site-url.lua to be named absolute-links. Add this snippet to soupault.conf:
[plugins.absolute-links]
file = "plugins/site-url.lua"
It will register the plugin as a widget named absolute-links.
Then you can use it like any other widget. Plugin subtable name becomes the name of the widget, in our case absolute-links.
[widgets.make-urls-absolute]
widget = "absolute-links"
site_url = "https://www.example.com"
If you want to write your own plugins, read on.
→ Plugin example
Here’s the source of that Site URL plugin that converts relative links to absolute URLs by prepending a site URL to them:
-- Converts relative links to absolute URLs
-- e.g. "/about" -> "https://www.example.com/about"
-- Get the URL from the widget config
site_url = config["site_url"]
if not Regex.match(site_url, "(.*)/$") then
site_url = site_url .. "/"
end
links = HTML.select(page, "a")
-- Lua array indices start from 1
local index = 1
while links[index] do
link = links[index]
href = HTML.get_attribute(link, "href")
if href then
-- Check if URL schema is present
if not Regex.match(href, "^([a-zA-Z0-9]+):") then
-- Remove leading slashes
href = Regex.replace(href, "^/*", "")
href = site_url .. href
HTML.set_attribute(link, "href", href)
end
end
index = index + 1
end
In short:
-
Widget options can be retrieved from the
configtable. -
The element tree of the page is in the
pagevariable. You can think of it as an equivalent ofdocumentin JavaScript. -
HTML.select()function is likedocument.querySelectorAllin JS. -
The
HTMLmodule provides an API somewhat similar to the DOM API in browsers, though it’s procedural rather than object-oriented.
→ Plugin environment
Plugins have access to the following global variables:
- page
- The page element tree that can be manipulated with functions from the HTML module.
- page_file
- Page file path, e.g. site/index.html
- target_dir
- The directory where the page file will be saved, e.g. build/about/.
- nav_path
-
A list of strings representing the logical nativation path. For example, for site/foo/bar/quux.html it's
["foo", "bar"]. - page_url
-
Relative page URL, e.g. /articles or /articles/index.html, depending on the
clean_urlssetting. - config
- A table with widget config options.
- soupault_config
-
The global soupault config (deserialized contents of
soupault.conf). - site_index
- Site index data structure
→ Plugin API
→ HTML
→ Element creation and destructuring
→ HTML.parse(string)
Example: h = HTML.parse("<p>hello world<p>")
Parses a string into an HTML element tree.
→ HTML.create_element(tag, text)
Example: h = HTML.create_element("p", "hello world")
Creates an HTML element node.
→ HTML.create_text(string)
Example: h = HTML.create_text("hello world")
Creates a text node that can be inserted into the page just like element nodes. This function automatically escapes all HTML special characters inside the string.
→ HTML.inner_html(html)
Example: h = HTML.inner_html(HTML.select(page, "body"))
Returns element content as a string.
→ HTML.strip_tags(html)
Example: h = HTML.strip_tags(HTML.select(page, "body"))
Returns element content as a string, with all HTML tags removed.
→ Element tree queries
→ HTML.select(html, selector)
Example: links = HTML.select(page, "a")
Returns a list of elements matching specified selector.
→ HTML.select_one(html, selector)
Example: content_div = HTML.select(page, "div#content")
Returns the first element matching specified selector, or nil if none are found.
→ HTML.select_any_of(html, selectors)
Example: link_or_pic = HTML.select_any_of(page, {"a", "img"})
Returns the first element matching any of specified selectors.
→ HTML.select_all_of(html, selectors)
Example: links_and_pics = HTML.select_all_of(page, {"a", "img"})
Returns all elements matching any of specified selectors.
→ Access to surrounding elements
→ HTML.parent(elem)
Returns element’s parent.
Example: if there’s an element that has a <blink> in it, insert a warning just before that element.
blink_elem = HTML.select_one(page, "blink")
if elem then
parent = HTML.parent(blink_elem)
warning = HTML.create_element("p", "Warning: blink element ahead!")
HTML.insert_before(parent, warning)
end
→ HTML.children(elem)
→ HTML.ancestors(elem)
→ HTML.descendants(elem)
→ HTML.siblings(elem)
Example: add class="silly-class" to every element inside the page <body>.
body = HTML.select_one(page, "body")
children = HTML.children(body)
local i = 1
while children[i] do
if HTML.is_element(children[i]) then
HTML.add_class(children[i], "silly-class")
end
i = i + 1
end
→ Tag and attribute manipulation
→ HTML.is_element
Web browsers provide a narrower API than general purpose HTML parsers. In the JavaScript DOM API, element.children provides access to all child elements of an element.
However, in the HTML parse tree, the picture is more complex. Text nodes are also child nodes—browsers just filter those out because JavaScript code rarely has a need to do anything with text nodes.
Consider this HTML: <p>This is a <em>great</em> paragraph</p>. How many children does the <p> element have? In fact, three: text("This is a "), element("em", "great"), text(" paragraph").
The goal of soupault is to allow modifying HTML pages in any imagineable ways, so it cannot ignore this complexity. Many operations like HTML.add_class still make no sense for text nodes, so there has to be a way to check if something is an element or not.
That’s where HTML.is_element comes in handy.
→ HTML.get_tag_name(html_element)
Returns the tag name of an element.
Example:
link_or_pic = HTML.select_any_of(page, {"a", "img"})
tag_name = HTML.get_tag_name(link_of_pic)
→ HTML.set_tag_name(html_element)
Changes the tag name of an element.
Example: ”modernize” <blink> elements by converting them to <span class="blink">.
blinks = HTML.select(page, "blink")
local i = 1
while blinks[i] do
elem = blinks[i]
HTML.set_tag_name(elem, "span")
HTML.add_class(elem, "blink")
i = i + 1
end
→ HTML.get_attribute(html_element, attribute)
Example: href = HTML.get_attribute(link, "href")
Returns the value of an element attribute. The first argument must be an element reference produced by HTML.select_one or another function.
If the attribute is missing, it returns nil. If the attribute is present but its value is empty (like in <elem attr=""> or <elem attr>), it returns an empty string.
In Lua, both empty strings and nil are false for the purpose of if value then ... end, so if you want to check for presence of an attribute regardless of its value, you should explicitly check for nil.
→ HTML.set_attribute(html_element, attribute, value)
Example: HTML.set_attribute(content_div, "id", "content")
Sets an attribute value.
→ HTML.add_class(html_element, class_name)
Example: HTML.add_class(p, "centered")
→ HTML.remove_class(html_element, class_name)
Example: HTML.remove_class(p, "centered")
→ Element tree modification
→ HTML.append_child(parent, child)
→ HTML.prepend_child(parent, child)
These functions insert the child element after the last or before the first child element of the parent.
Example: HTML.append_child(page, HTML.create_element("br"))
→ HTML.insert_before(old, new)
→ HTML.insert_after(old, new)
Insert the new element right before or after the old element.
→ HTML.replace_content(parent, child)
Delete all children of the parent and insert the child element in their place.
→ HTML.delete(element)
Example: HTML.delete(HTML.select_one(page, "h1"))
Deletes an element from the page.
→ HTML.delete_content(element)
Deletes all children of an element (but leaves the element itself in place).
→ HTML.clone_content(html_element)
Creates a new element tree from the content of an element.
Useful for duplicating an element elsewhere in the page.
→ Convenience functions
→ HTML.get_heading_level(element)
For elements whose tag name matches <h[1-9]> pattern, returns the heading level.
Returns zero for elements whose tag name doesn’t look like a heading and for values that aren’t HTML elements.
→ HTML.get_headings_tree(element)
Returns a table that represents the tree of HTML document headings in a format like this:
[
{
"heading": ...,
"children": [
{"heading": ..., "children": []}
]
},
{"heading": ..., "children": []}
]
Values of the heading fields are HTML element references. Perfect for those who want to implement their own ToC generator.
→ Behaviour
If an element tree access function cannot find any elements (e.g. there are no elements that match a selector), it returns nil.
If a function that expects an HTML element receives nil, it immediately returns nil,
so you don’t need to check for nil at every step and can safely chain calls to those functions2.
→ Regex
Regular expressions used by this module are mostly Perl-compatible. Capturing groups and back references are not supported.→ Regex.match(string, regex)
Example: Regex.match("/foo/bar", "^/")
Checks if a string matches a regex.
→ Regex.find_all(string, regex)
Example: matches = Regex.find_all("/foo/bar", "([a-z]+)")
Returns a list of substrings matching a regex.
→ Regex.replace(string, regex, string)
Example: s = Regex.replace("/foo/bar", "^/", "")
Replaces the first occurence of a matching substring. It returns a new string and doesn’t modify the original.
→ Regex.replace_all(string, regex, string)
Example: Regex.replace_all("/foo/bar", "/", "")
Replaces every matching substring. It returns a new string and doesn’t modify the original.
→ Regex.split(string, regex)
Example: substrings = Regex.split("foo/bar", "/")
Splits a string at a separator.
→ String
→ String.trim(string)
Example: String.trim(" my string ") produces "my string"
Removes leading and trailing whitespace from a string.
→ String.slugify_ascii(string)
Example: String.slugify_ascii("My Heading") produces "my-heading"
Replaces all characters other than English letters and digits with hyphens, exactly like the ToC widget.
→ String.truncate(string, length)
Truncates a string to a given length.
Example: String.truncate("foobar", 3) produces "foo".
→ String.to_number(string)
Example: String.to_number("2.7") produces 2.7 (float).
Converts strings to numbers. Returns nil is a string isn’t a valid representation of a number.
→ String.join(separator, list)
Concatenates a list of strings.
Example: String.join(" ", {"hello", "world"}).
→ String.render_template(template_string, env)
Renders data using a jingoo template.
Example:
env = {}
env["greeting"] = "hello"
env["addressee"] = "world"
s = String.render_template("{{greeting}} {{addressee}}", env)
→ String.base64_encode
Encodes a string in Base64.
→ String.base64_decode
Decodes Base64 data.
→ Sys
→ Sys.read_file(path)
Example: Sys.read_file("site/index.html")
Reads a file into a string. The path is relative to the working directory.
→ Sys.write_file(file_path, data)
Writes data to a file. If a file doesn’t exist, it will be created. If a file already exists, it will be overwritten.
→ Sys.delete_file(path)
Deletes a file.
→ Sys.delete_recursive(path)
Deletes a file or a directory recursively.
→ Sys.get_file_size(file_path)
Returns file size in bytes. Returns nil if it cannot read the file
(whether because it doesn’t exist or due to permission errors).
→ Sys.file_exists(file_path)
Checks if a file exists.
→ Sys.is_file(file_path)
Checks if a path is a regular file (not a directory). Returns nil if the file path does not exist at all.
→ Sys.is_dir(file_path)
Checks if a path is a directory. Returns nil if the file path does not exist at all.
→ Sys.get_extension(file_path)
Returns the file extension, if it has one. For files without an extension it returns an empty string.
For files with multiple extensions like .tar.bz2, returns the last extension.
Examples:
-
"cat.jpg" → "jpg" -
"/bin/bash" → "" -
"soupault.tar.gz" → "gz"
→ Sys.basename(file_path)
Returns the base name of a path (its file name part), e.g. "/usr/local/bin/soupault" → "soupault".
→ Sys.dirname(file_path)
Returns the directory name of a path, e.g. "/usr/local/bin/soupault" → "/usr/local/bin".
→ Sys.join_path(left, right)
Joins two file paths, using a correct, OS-specific separator.
E.g. Sys.join_path("directory", "file") will produce directory/file on UNIX, but directory\file on Windows.
Note: This function will not replace existing separators in its arguments.
You also should not use this function for concatenating URLs, at least not when using soupault on Windows.
→ Sys.run_program(command)
Executes given command in the system shell.
Returns 1 (sic!) on success, nil on failure, so that if Sys.run_program(...) statements work as expected.
The output of the command is ignored. If command fails, its stderr is logged.
Example: create a silly file in the directory where generated page will be stored.
res = Sys.run_program(format("echo \"Kilroy was here\" > %s/graffiti", target_dir))
if not res then
Log.warning("Damn, busted")
end
The intended use case for it is creating and processing assets, e.g. converting images to different formats.
There’s also Sys.run_program_get_exit_code that does the same, but returns the raw exit code (0 on success).
→ Sys.get_program_output(command)
Executes a command in the system shell and returns its output.
If the command fails, it returns nil. The stderr is shown in the execution log, but there’s no way a plugin can access its stderr or the exit code.
Example: getting the last modification date of a page from git.
git_command = "git log -n 1 --pretty=format:%ad --date=format:%Y-%m-%d -- " .. page_file
timestamp = Sys.get_program_output(git_command)
if not timestamp then
timestamp = "1970-01-01"
end
→ Sys.random(max)
Example: Sys.ranrom(1000)
Generates a random number from 0 to max.
→ Sys.is_unix()
Returns true on UNIX-like systems (Linux, Mac OS, BSDs), false otherwise.
→ Sys.is_windows()
Returns true on Microsoft Windows, false otherwise.
→ Plugin
Provides functions for communicating with the plugin runner code.→ Plugin.fail(message)
Example: Plugin.fail("Error occured")
Stops plugin execution immediately and signals an error. Errors raised this way are treated as widget processing errors by soupault, for the purpose of the strict option.
→ Plugin.exit(message)
Example: Plugin.exit("Nothing to do"), Plugin.exit()
Stops plugin execution immediately. The message is optional. This kind of termination is not considered an error by soupault.
→ Plugin.require_version(version_string)
Example: Plugin.require_version("1.8.0")
Stops plugin execution if soupault is older than the required version.
You can use a full version like 1.9.0 or a short version like 1.9. This function was introduced in 1.8, so plugins that use it will fail to work in 1.7 and older.
→ Plugin.soupault_version()
Returns soupault version string (e.g. "2.2.0").
→ Log
→ Log.debug(message)
Displayed with a [DEBUG] prefix when debug under [settings] is true.
→ Log.info(message)
Displayed with an [INFO] prefix if verbose or debug is true.
→ Log.warning(message)
→ Log.error(message)
These levels are always on and cannot be silenced.
→ JSON
→ JSON.from_string(string)
Parses a JSON string and returns a table. Fails plugin execution if string isn’t syntactically correct JSON data.
→ JSON.unsafe_from_string(string)
Same as JSON.from_string, but returns nil on parse errors. Parse error message is logged (warning level).
Note that there are valid JSON strings that parse to nil (e.g. "null"), so nil doesn’t always mean a parse error.
→ JSON.to_string(value)
Converts a Lua value to JSON. The value doesn’t have to be a table, any value will work.
It produces minified JSON.
→ JSON.pretty_pring(value)
Same as JSON.to_string but produces human-readable, indented JSON.
→ Date
→ Date.now_timestamp()
Returns a UNIX timestamp (seconds passed since 1970-01-01 00:00 UTC).
→ Date.now_format(fmt)
Returns as a string representation of the current datetime in UTC.
Example: Date.now_format("%Y-%m-%d %H:%M")
→ Date.to_timestamp(date_string, input_formats)
Converts a datetime string to a UNIX timestamp, using a list of allowed datetime formats.
Returns nil if none of the formats match the datetime string.
Example: Date.to_timestamp("2006-08-16", {"%Y-%m-%d"})
→ Date.reformat(date_string, input_formats, output_format)
Parses and reformats a datetime string.
Example: Date.reformat("2007-06-23", {"%Y-%m-%d", "%d.%m.%Y"}, "%Y/%d/%m")
→ Table
→ Table.has_key(table, key)
Returns nil if and only if table does not have a field key.
Why is this function needed? There are two possible reasons why if my_table["some_key"] then may not run:
-
my_tabledoes not have a fieldsome_key -
my_tableshas a fieldsome_keybut its truth value is false.
This functions tells you for certain.
→ Table.iter(func, table)
Executes a function func(key, value) for every item in a table.
Example:
my_table = {}
my_table["foo"] = 0
my_table["bar"] = "quux"
my_table["baz"] = {1,2}
function show_pair(k, v)
Log.debug(format("Key: %s, value: %s", k, JSON.to_string(v)))
end
Table.iter(show_pair, my_table)
→ Table.iter_values(func, table)
Executes a function func(key) for every key in a table.
→ Table.fold(func, table, initial_value)
Folds a table using a func(key, value, accumulator) function.
Since tables are not ordered collections, the question whether it’s a left or right fold is meaningless.
→ Table.fold_values(func, table, initial_value)
Folds a table using a func(value, accumulator) function.
→ Table.apply(func, table)
Applies func(key, value) to every table item, in place. That is, executes table[key] = func(key, value) for every key.
Can be seen as an imperative equivalent of map.
Since assigning nil to a field is equivalent to deleting that field from a table, this function can be used as ab in-place filter too.
→ Glossary
- jingoo
- A logic-aware template processor with syntax and capabilities similar to Jinja2. You can find the details in its documentation.
- limiting option
-
Many configuration items like widgets and index views can be limited to specific pages. Using
page, section, path_regexoptions you can enable something only for some pages. Usingexclude_page, exclude_section, exclude_path_regexoptions, you can enable something for all pages except some. You can also combine those options. All those options take a single string or a list of strings. Examples:page = ["foo.html", "bar.html"],section = "blog/",exclude_path_regex = '^(.*)/index\.html$'. - action
-
Action defines what to do with the content. In inclusion widgets (
include,insert_html,exec,preprocess_element) it's defined by theactionoption, in[settings]it'sdefault_content_action, and in custom templates it'scontent_action.
Its possible values are:prepend_child,append_child,insert_before,insert_after,replace_content,replace_element. - site directory
-
The directory where page and asset source files are stored. By default it's
site/. You can change it withsite_diroption under[settings]. - system shell
-
/bin/shon UNIX,cmd.exeon Microsoft Windows. -
Logical navigation path for the page. For example, for
site/papers/programming/goto-considered-harmful.htmlit's[papers, programming].